The repository for paper 'Task-Oriented Communications for Visual Navigation with Edge-Aerial Collaboration in Low Altitude Economy'.
To support the Low Altitude Economy (LAE), it is essential to achieve precise localization of unmanned aerial vehicles (UAVs) in urban areas where global positioning system (GPS) signals are unavailable. Vision-based methods offer a viable alternative but face severe bandwidth, memory and processing constraints on lightweight UAVs.
Inspired by mammalian spatial cognition, we propose a task-oriented communication framework, where UAVs equipped with multi-camera systems extract compact multi-view features and offload localization tasks to edge servers. We introduce the Orthogonally-constrained Variational Information Bottleneck encoder (O-VIB), which incorporates automatic relevance determination (ARD) to prune non-informative features while enforcing orthogonality to minimize redundancy. This enables efficient and accurate localization with minimal transmission cost.
Extensive evaluation on a dedicated LAE UAV dataset shows that O-VIB achieves high-precision localization under stringent bandwidth budgets.
-
carla_multi_view/– CARLA-based multi-view data collector
Connects to CARLA in synchronous mode, spawns five rigidly mounted sensors (RGB, depth, semantic) on the UAV chassis, follows road-aligned waypoints, and writes aligned multi-view frames plus metadata to disk. -
edge_database_encoder/– Edge-side feature database builder
Uses CLIP to encode the collected RGB frames, stores per-view descriptors, and aggregates averaged embeddings inside a FAISS index with coordinate supervision. -
uav_lightweight_encoder/– Lightweight VIB encoder for UAV transmission
Contains the single-view and multi-view VIB models, training helpers, and CLI tools to compress the multi-view feature tensors into compact latent codes before uplink.
Each folder only keeps the production code required for the above stages—debug scripts, Chinese logs, and ad-hoc experiments were intentionally removed.
python -m carla_multi_view.collector
Tune CollectorSettings inside carla_multi_view/collector.py to change the CARLA map, altitude, sampling distance, or output root. The collector:
- configures the CARLA world in synchronous mode and keeps the traffic manager aligned,
- spawns five cameras with RGB/depth/semantic modalities and keeps them rigidly attached to the UAV body,
- samples road-following waypoints via
RoadWaypointPlanner, - saves RGB PNGs, depth
.npy+ log-depth PNGs, semantic PNGs, and frame-level metadata JSON files under the configured dataset directory.
python -m edge_database_encoder.build_database \
--dataset_path /path/to/collected_dataset \
--output_path /path/to/database_output \
--model_name "ViT-B/32" \
--device cuda
The script loads RGB frames plus metadata, extracts CLIP features view-by-view, stores them in view_features/<camera>/<frame>.npz, and creates a FAISS index alongside dataset statistics for downstream localization. Use validate_database to sanity-check the exported index.
Training
python -m uav_lightweight_encoder.train_vib \
--feature_dir /path/to/database_output \
--output ovib_multiview.pt \
--mode multi \
--latent_dim 64 \
--hidden_dims 512 256 \
--epochs 50 \
--batch_size 128
Compression
python -m uav_lightweight_encoder.compress \
--feature_dir /path/to/database_output \
--weights ovib_multiview.pt \
--output /path/to/latent_codes
The training CLI covers both single-view and multi-view VIB models, while compress.py loads a trained checkpoint and exports per-frame latent codes ready for transmission.
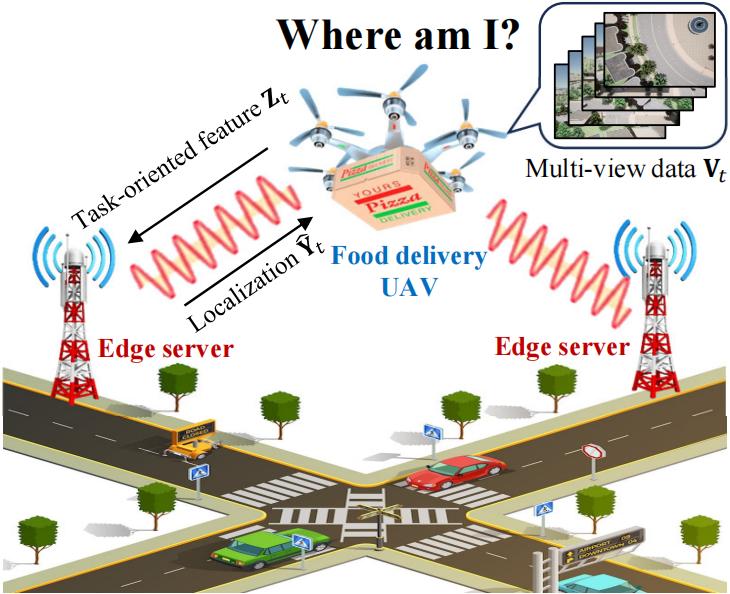
Our system operates in a UAV-edge collaborative framework designed for GPS-denied urban environments. The model consists of:
- Multi-camera UAV System: Captures multi-directional views (Front, Back, Left, Right, Down) for comprehensive spatial awareness
- Edge Server Infrastructure: Maintains a geo-tagged feature database, enabling efficient localization
- Communication-Efficient Design: Optimizes the trade-off between localization accuracy and bandwidth consumption
The UAV captures multi-view images at each time step, extracts high-dimensional features through a feature extractor, and transmits compressed representations to edge servers. Our objective is to minimize localization error while keeping communication costs below a specified threshold.
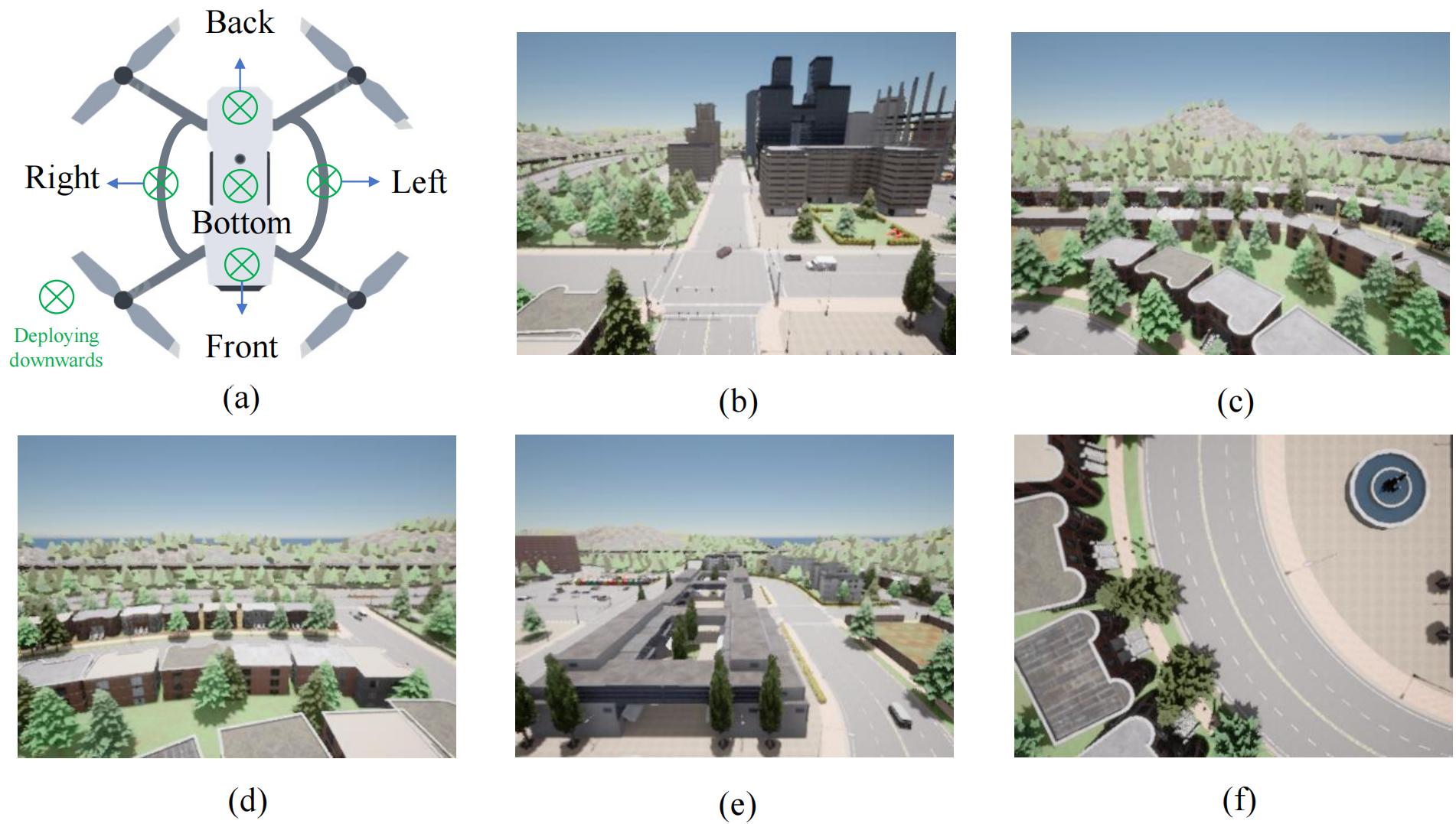
We collected a comprehensive dataset using the CARLA simulator to facilitate research on multi-view UAV visual navigation in GPS-denied environments:
- Environments: 8 representative urban maps in CARLA
- Collection Method: UAV flying at constant height following road-aligned waypoints with random direction changes
- Camera Configuration: 5 onboard cameras capturing different angles and directions
- Image Types: RGB, semantic, and depth images at 400×300 pixel resolution
- Scale: 357,690 multi-view frames with precise localization and rotation labels
- Hardware: Collected using 4×RTX 5000 Ada GPUs



The dataset provides a realistic simulation of UAV flight in urban environments where GPS signals might be compromised or unavailable.
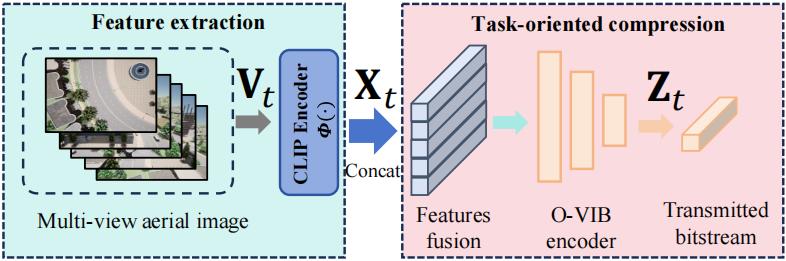
Our feature extraction pipeline is designed for robust multi-view feature extraction under limited bandwidth:
- CLIP-based Vision Backbone: Utilizes CLIP Vision Transformer (ViT-B/32) pretrained on large-scale natural image-text pairs
- Feature Processing: Each image undergoes preprocessing (resize, normalize, tokenize) before feature extraction
- Normalization: Features are normalized to lie on the unit hypersphere, improving numerical stability and facilitating cosine similarity-based retrieval
- Multi-view Feature Tensor: Final representation constructed by concatenating view-wise embeddings, capturing a rich panoramic representation of the UAV's surroundings
This pipeline creates a memory base for the visual navigation system, enabling efficient localization with minimal communication overhead.
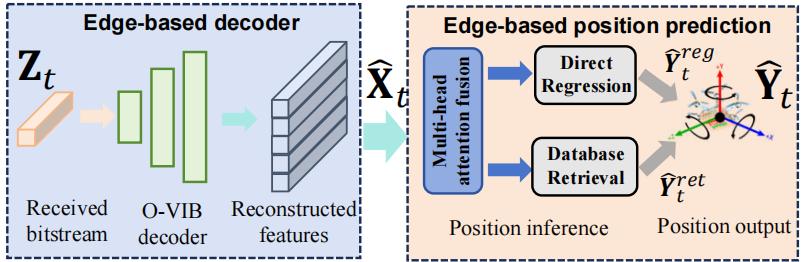
The edge server receives compressed representations from the UAV and estimates the UAV's position using a sophisticated multi-view attention fusion mechanism:
- Multi-view Attention Fusion: Integrates information from multiple camera views
- Hybrid Estimation Method: Combines direct regression and retrieval-based inference
- Adaptive Weighting: Balances regression and retrieval estimates based on confidence scores
- Geo-tagged Database: Utilized for querying position information
This end-to-end pipeline optimizes the trade-off between localization accuracy and communication efficiency, enabling precise UAV navigation in GPS-denied environments with constrained wireless bandwidth.
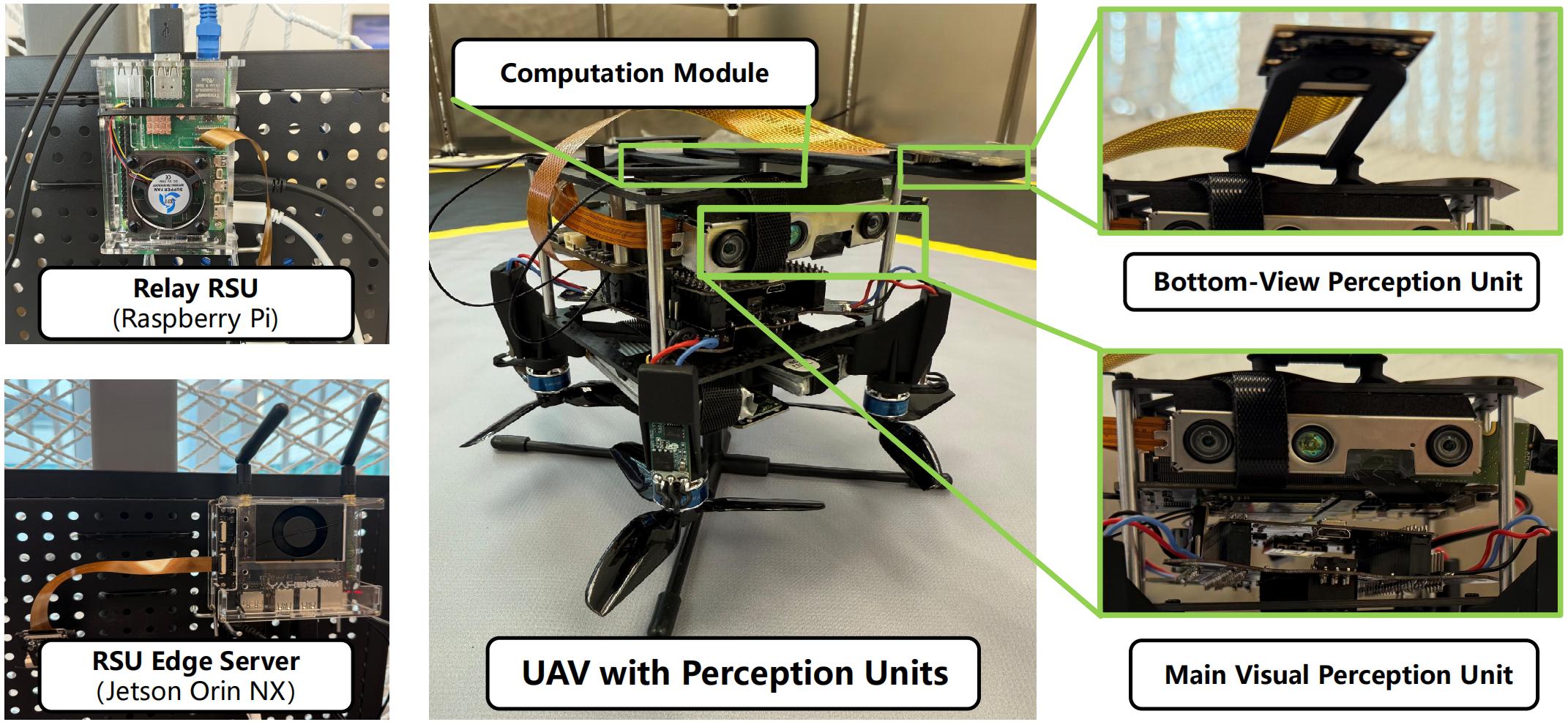
We validated our approach using a physical testbed with real hardware components:
- UAV Compute: Jetson Orin NX 8GB for encoding five camera streams
- Communication: IEEE 802.11 wireless transmission to nearby roadside units (RSUs)
- Relay RSU: Raspberry Pi 5 16GB that forwards data via Gigabit Ethernet to cloud edge servers when overloaded
- Edge RSU: Jetson Orin NX Super 16GB performing on-board inference
This hardware implementation allowed us to evaluate algorithm encoding/decoding complexity and latency in real-world conditions, confirming that our O-VIB framework delivers high-precision localization with minimal bandwidth usage.

The green dot represents the Ground Truth (GT), which is the actual coordinate of the UAV. The red dot represents the Top 1 prediction (Pred), which is the most accurate prediction. However, Top 2 and Top 3 are alternative prediction locations provided by the algorithm, but their accuracy is usually much lower than the Top 1 prediction.
Our research is detailed in the paper: Task-Oriented Communications for Visual Navigation with Edge-Aerial Collaboration in Low Altitude Economy
This project is licensed under the MIT License - see the LICENSE file for details.
This work of Y. Fang was supported in part by the Hong Kong SAR Government under the Global STEM Professorship and Research Talent Hub, the Hong Kong Jockey Club under the Hong Kong JC STEM Lab of Smart City (Ref.: 2023-0108). This work of J. Wang was partly supported by the National Natural Science Foundation of China under Grant No. 62222101 and No. U24A20213, partly supported by the Beijing Natural Science Foundation under Grant No. L232043 and No. L222039, partly supported by the Natural Science Foundation of Zhejiang Province under Grant No. LMS25F010007. The work of S. Hu was supported in part by the Hong Kong Innovation and Technology Commission under InnoHK Project CIMDA. The work of Y. Deng was supported in part by the National Natural Science Foundation of China under Grant No. 62301300.
For any questions or discussions, please open an issue or contact us at zhefang4-c [AT] my [DOT] cityu [DOT] edu [DOT] hk.