




DAJIN2 is a genotyping tool for genome-edited samples using nanopore-targeted sequencing.
DAJIN2 takes its name from the Japanese phrase 一網打尽 (Ichimou DAJIN in Japanese; Yīwǎng Dǎjìn in Chinese),
meaning “to capture everything in a single sweep.”
This reflects the tool’s design philosophy: comprehensive detection of both intended and unintended genome editing outcomes in one analysis.
-
Comprehensive Mutation Detection
DAJIN2 can detect a wide range of genome editing events in nanopore-targeted regions, from point mutations to structural variants.
It is particularly effective at identifying unexpected mutations and complex mutations, such as insertions within deleted regions. -
Highly Sensitive Allele Classification
Supports classification of mosaic alleles, capable of detecting minor alleles present at approximately 1%. -
Intuitive Visualization
Genome editing results are visualized in an intuitive manner, enabling rapid and easy identification of mutations. -
Multi-Sample Support
Batch processing of multiple samples is supported, allowing efficient execution of large-scale experiments and comparative studies. -
Simple Installation and Operation
Requires no specialized computing environment and runs smoothly on a standard laptop.
Easily installable via Bioconda or PyPI, and usable via the command line.
- Runs on a standard laptop
- Recommended memory: 16 GB or more
Note
DAJIN2 is the successor to DAJIN, which required a GPU for efficient computation due to its use of deep learning.
In contrast, DAJIN2 does not use deep learning and does not require a GPU.
Therefore, it runs smoothly on typical laptops.
- Python 3.10-3.12
- Unix-based environment (Linux, macOS, WSL2, etc.)
Important
For Windows Users
DAJIN2 is designed to run in a Linux environment.
If you are using Windows, please use WSL2 (Windows Subsystem for Linux 2).
From Bioconda (Recommended)
conda create -y -n env-dajin2 -c conda-forge -c bioconda DAJIN2
conda activate env-dajin2From PyPI
pip install DAJIN2Important
DAJIN2 is actively being developed and improved.
Please make sure you are using the latest version to take advantage of the newest features.
1. To check your current version
DAJIN2 --version2. Check the latest version
https://github.com/akikuno/DAJIN2/releases
3. Reinstall DAJIN2 if the installed version is not the latest
conda deactivate
conda remove -y -n env-dajin2 --all
conda create -y -n env-dajin2 -c conda-forge -c bioconda DAJIN2
conda activate env-dajin2or
pip install -U DAJIN2Caution
If you encounter any issues during the installation, please refer to the Troubleshooting Guide
In DAJIN2, a control that has not undergone genome editing is necessary to detect genome-editing-specific mutations. Specify a directory containing the FASTQ/FASTA (both gzip compressed and uncompressed) or BAM files of the genome editing sample and control.
Basecalling with Dorado
- For basecalling with Dorado (
dorado basecalleranddorado demux), the following file structure will be output:
bam_pass
├── barcode01
│ └── EXP-PBC096_barcode01.bam
├── barcode02
│ └── EXP-PBC096_barcode02.bam
├── ...
└── unclassified
│ └── EXP-PBC096_unclassified.bam
Important
Store each BAM file in a separate directory.
The directory names can be set arbitrarily.
Tip
For detailed Dorado usage, see DORADO_HANDLING.md.
- Similarly, store the FASTA files outputted after sequence error correction with
dorado correctin separate directories.
dorado_correct
├── barcode01
│ └── EXP-PBC096_barcode01.fasta
└── barcode02
└── EXP-PBC096_barcode02.fasta
Note
Correction with dorado correct may mask minor editing outcomes that can arise from genome editing.
Therefore, unless dorado correct is required, we recommend using the BAM files output by dorado basecaller and dorado demux.
Basecalling with Guppy
After basecalling with Guppy, the following file structure will be output:
fastq_pass
├── barcode01
│ ├── fastq_runid_b347657c88dced2d15bf90ee6a1112a3ae91c1af_0_0.fastq.gz
│ ├── fastq_runid_b347657c88dced2d15bf90ee6a1112a3ae91c1af_10_0.fastq.gz
│ └── fastq_runid_b347657c88dced2d15bf90ee6a1112a3ae91c1af_11_0.fastq.gz
└── barcode02
├── fastq_runid_b347657c88dced2d15bf90ee6a1112a3ae91c1af_0_0.fastq.gz
├── fastq_runid_b347657c88dced2d15bf90ee6a1112a3ae91c1af_10_0.fastq.gz
└── fastq_runid_b347657c88dced2d15bf90ee6a1112a3ae91c1af_11_0.fastq.gz
Caution
Although DAJIN2 can process Guppy-generated data, Guppy is no longer supported by Oxford Nanopore Technologies.
Please use Dorado for basecalling and demultiplexing.
The FASTA file should contain descriptions of the alleles anticipated as a result of genome editing.
Important
A header name >control and its sequence are necessary.
If there are anticipated alleles (e.g., knock-ins or knock-outs), include their sequences in the FASTA file too. These anticipated alleles can be named arbitrarily.
Below is an example of a FASTA file:
>control
ACGTACGTACGTACGT
>knock-in
ACGTACGTCCCCACGTACGT
>knock-out
ACGTACGT
Here, >control represents the sequence of the control allele, while >knock-in and >knock-out represent the sequences of the anticipated knock-in and knock-out alleles, respectively.
Important
Ensure that both ends of the FASTA sequence match those of the amplicon sequence.
If the FASTA sequence is longer or shorter than the amplicon, the difference may be recognized as an indel.
Note
BED file is an optional.
If the reference genome is not from UCSC, or if the external servers that DAJIN2 depends on (UCSC Genome Browser and GGGenome) are unavailable, you can specify a BED file using the -b/--bed option to run offline.
Tip
Access to the UCSC Genome Browser or GGGenome servers may occasionally be unavailable. Therefore, we generally recommend using -b/--bed instead of --genome.
When using the -b/--bed option with a BED file, please ensure:
Use BED6 format (6 columns required):
chr1 1000000 1001000 mm39 195154279 +
Column descriptions:
- Column 1: Chromosome name (e.g., chr1, chr2)
- Column 2: Start position (0-indexed)
- Column 3: End position (0-indexed)
- Column 4: Name (genome ID)
- Column 5: Score (chromosome size for proper IGV visualization)
- Column 6: Strand (+ or -, must match FASTA allele orientation)
Note
For the score field (column 5), please enter the size of the chromosome specified in column 1.
While the original BED format limits scores to 1000, DAJIN2 accepts chromosome sizes without any issue.
Note
Chromosome sizes can be found at:
https://hgdownload.soe.ucsc.edu/goldenPath/[genome]/bigZips/[genome].chrom.sizes
(e.g., https://hgdownload.soe.ucsc.edu/goldenPath/mm39/bigZips/mm39.chrom.sizes)
Important
Strand orientation must match. The strand field (column 6: + or -) in your BED file must match the strand orientation of your FASTA allele sequences.
- If your FASTA allele sequence is on the forward strand (5' to 3'), use
+in the BED file - If your FASTA allele sequence is on the reverse strand (3' to 5'), use
-in the BED file
Tip
For detailed BED file usage, see BED_COORDINATE_USAGE.md.
DAJIN2 supports single-sample analysis (one sample vs one control).
DAJIN2 <-c|--control> <-s|--sample> <-a|--allele> <-n|--name> \
[-g|--genome] [-b|--bed] [-t|--threads] [--no-filter] [-h|--help] [-v|--version]
Options:
-c, --control Specify the path to the directory containing a control FASTQ/FASTA/BAM file.
-s, --sample Specify the path to the directory containing a sample FASTQ/FASTA/BAM file.
-a, --allele Specify the path to the FASTA file.
-n, --name (Optional) Set the output directory name. Default: 'Results'.
-b, --bed (Optional) Specify the path to BED6 file containing genomic coordinates. Default: '' (empty string).
-g, --genome (Optional) Specify the reference UCSC genome ID (e.g., hg38, mm39). Default: '' (empty string).
-t, --threads (Optional) Set the number of threads. Default: 1.
--no-filter (Optional) Disable minor allele filtering (keep alleles below 0.5%). Default: False.
-h, --help Display this help message and exit.
-v, --version Display the version number and exit.# Download the example dataset
curl -LJO https://github.com/akikuno/DAJIN2/raw/main/examples/example_single.tar.gz
tar -xf example_single.tar.gz
# Run DAJIN2
DAJIN2 \
--control example_single/control \
--sample example_single/sample \
--allele example_single/stx2_deletion.fa \
--name stx2_deletion \
--bed example_single/stx2_deletion.bed \
--threads 4By default, DAJIN2 filters out alleles with read counts below 0.5% (5 reads out of 100,000 downsampled reads) to reduce noise and improve accuracy. However, when analyzing rare mutations or somatic mosaicism where minor alleles may be present at very low frequencies, you can use the --no-filter option to disable this filtering.
When to use --no-filter:
- Detecting rare somatic mutations (< 0.5% frequency)
- Analyzing samples with suspected low-level mosaicism
- Research requiring detection of all possible alleles regardless of frequency
Usage:
DAJIN2 \
--control example_single/control \
--sample example_single/sample \
--allele example_single/stx2_deletion.fa \
--name stx2_deletion \
--bed example_single/stx2_deletion.bed \
--threads 4 \
--no-filterCaution
Using --no-filter may increase noise and false positives in the results. It is recommended to validate rare alleles through additional experimental methods.
By using the batch subcommand, you can process multiple samples simultaneously.
For this purpose, a CSV or Excel file consolidating the sample information is required.
Note
For guidance on how to compile sample information, please refer to this document.
Required columns: sample, control, allele, name
Optional columns: genome, bed (or genome_coordinate), and any custom columns
Example CSV with BED files:
sample,control,allele,name,bed
/path/to/sample1,/path/to/control1,/path/to/allele1.fa,experiment1,/path/to/coords1.bed
/path/to/sample2,/path/to/control2,/path/to/allele2.fa,experiment2,/path/to/coords2.bedTip
We recommend using the same name in the name column for sample sets you want to compare.
Sample sets with the same value in the name column are treated as a single group, and their outputs can be consolidated into one.
Here is an example 👉 batch.csv
DAJIN2 batch <-f|--file> [-t|--threads] [--no-filter] [-h]
Options:
-f, --file Specify the path to the CSV or Excel file.
-t, --threads (Optional) Set the number of threads. Default: 1.
--no-filter (Optional) Disable minor allele filtering (keep alleles below 0.5%). Default: False.
-h, --help Display this help message and exit.# Download the example dataset
curl -LJO https://github.com/akikuno/DAJIN2/raw/main/examples/example_batch.tar.gz
tar -xf example_batch.tar.gz
# Run DAJIN2 batch
DAJIN2 batch --file example_batch/batch.csv --threads 4DAJIN2 can launch a web app with the following command:
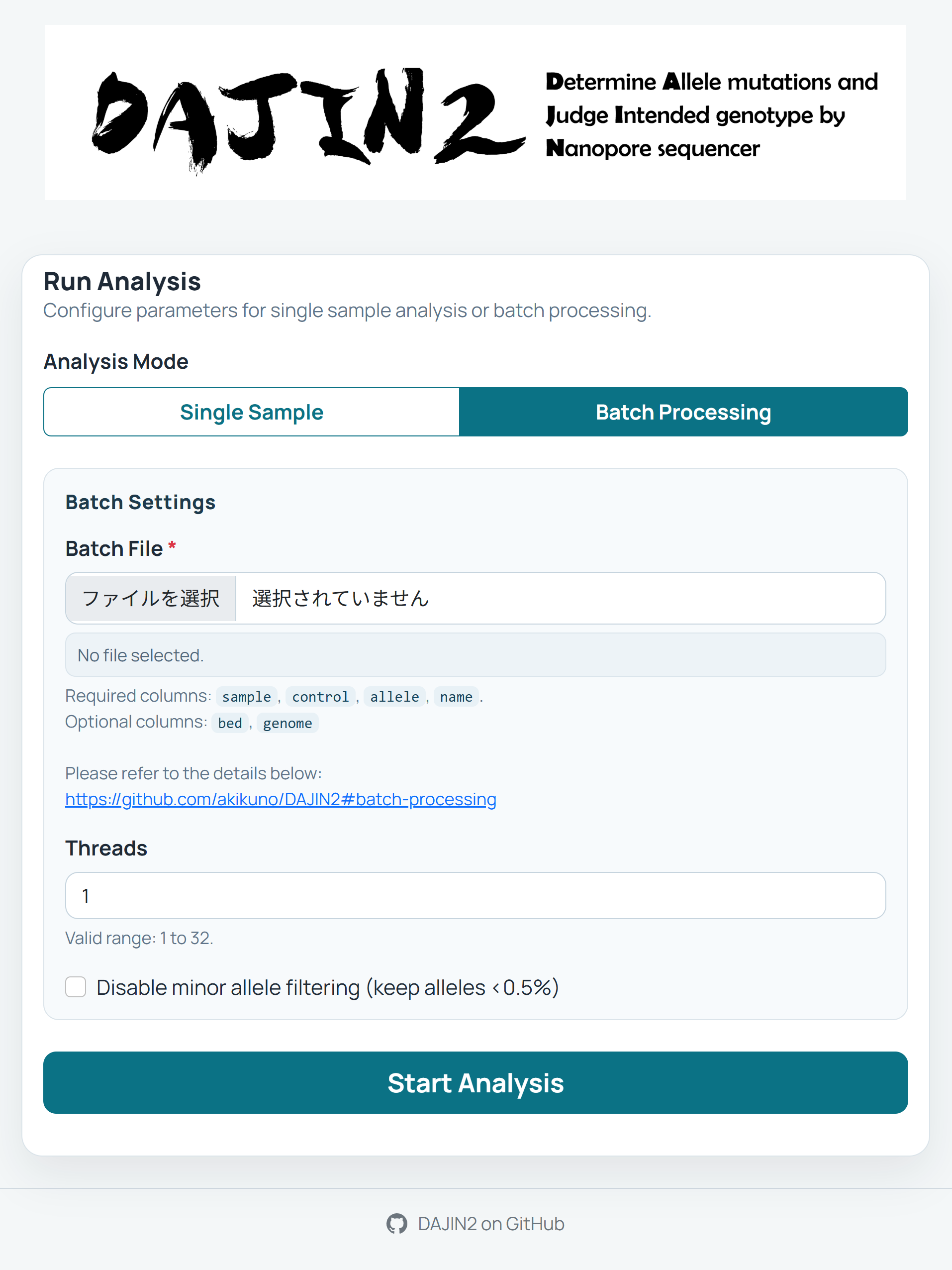
DAJIN2 guiWhen executed, your default web browser will open and display the following GUI at http://localhost:{PORT}/.
Note
If the browser does not launch automatically, please open your browser manually and navigate to http://localhost:{PORT}/.
-
Project Setup
- Project Name: Enter any analysis name
- Directory Upload: Select directories containing sample or control FASTQ/FASTA/BAM files
- Allele FASTA: Upload FASTA file containing expected allele sequences
- BED File (optional): Upload BED6 format file to specify genomic coordinates
- Reference Genome (optional): Specify UCSC genome ID (e.g.,
hg38,mm39)
-
Parameter Configuration
- Threads: Set the number of CPU threads to use
- No Filter: Enable to detect rare mutations below 0.5% frequency
-
Run Analysis
Click "Start Analysis" and progress will be displayed in real time. -
View Results
After completion, the output folder path will be displayed and result files will be accessible.
-
Prepare Batch File
Create a CSV or Excel file with columns:sample,control,allele,name. -
Upload Batch File
Use the "Batch Processing" tab to upload your configuration file. -
Parameter Configuration
- Threads: Set the number of CPU threads to use
- No Filter: Enable to detect rare mutations below 0.5% frequency
-
Run Analysis
Click "Start Analysis" and progress will be displayed in real time. -
View Results
After completion, the output folder path will be displayed and result files will be accessible.
Upon completion of DAJIN2 processing, a directory named DAJIN_Results/{NAME} is generated.
Inside the DAJIN_Results/{NAME} directory, the following files can be found:
DAJIN_Results/tyr-substitution
├── BAM
│ ├── control
│ ├── tyr_c230gt_01
│ ├── tyr_c230gt_10
│ └── tyr_c230gt_50
├── DAJIN2_log_20260127_140954_076887.txt
├── FASTA
│ ├── tyr_c230gt_01
│ ├── tyr_c230gt_10
│ └── tyr_c230gt_50
├── HTML
│ ├── tyr_c230gt_01
│ ├── tyr_c230gt_10
│ └── tyr_c230gt_50
├── MUTATION_INFO
│ ├── tyr_c230gt_01.csv
│ ├── tyr_c230gt_10.csv
│ └── tyr_c230gt_50.csv
├── VCF
│ ├── tyr_c230gt_01
│ ├── tyr_c230gt_10
│ └── tyr_c230gt_50
├── launch_report_mac.command
├── launch_report_windows.bat
└── read_summary.xlsx
On Windows, double-click launch_report_windows.bat.
On macOS, double-click launch_report_mac.command.
Your browser will open and display the report.

Demo video:
dajin2-tooltips-1080p.mp4
Tip
Clicking on an allele of interest in the stacked bar chart allows you to view detailed information on the mutation (right panel above on figure, and video).
In the report, Allele type indicates the allele category, and Percent of reads shows the proportion of reads.
Allele type categories:
- {Allele name}: Alleles that perfectly match a user-defined allele in the FASTA file
- {Allele name} with indels: Alleles similar to a user-defined allele but with a few-base substitution, deletion, insertion, or inversion
- unassigned insertion/deletion/inversion: Alleles with deletions, insertions, or inversions of 10 bases or more that are not defined by the user
Warning
In PCR amplicon sequencing, Percent of reads may not match the true allele proportions due to amplification bias.
This effect can be pronounced when large deletions are present, potentially distorting the actual allele ratios.
read_summary.xlsx lists the read counts and proportions for each allele.
The stacked bar chart in the report is a visualization of read_summary.xlsx.
Use it as reference when preparing figures for publications.
The BAM and VCF directories contain BAM and VCF files classified by allele.
Note
If --bed or --genome is not specified, reads are aligned to the control allele in the input FASTA file.
The FASTA directory stores FASTA files for each allele.
The HTML directory stores per-allele HTML files with color-highlighted mutations.
An example of a Tyr point mutation (green) is shown below:

DAJIN2 also extracts representative SV alleles (Insertion, Deletion, Inversion) in the sample and underlines SV regions.
Below is an example where a deletion (light blue) and an insertion (red) are observed at both ends of an inversion (purple underline).

We welcome your questions, bug reports, and feedback.
Please use the following Google Form to submit your report:
👉 Google Form
If you have a GitHub account, you can also submit reports via
👉 GitHub Issues
Please refer to CONTRIBUTING for how to contribute and how to verify your contributions.
Note
For frequently asked questions, please refer to this page.
Please note that this project is released with a Contributor Code of Conduct.
By participating in this project you agree to abide by its terms.
For more information, please refer to the following publication: